
اپیزود ۶ – یادگیری ماشین درخت تصمیم در فارکس Decision Tree
مقدمه: چرا «یادگیری ماشین درخت تصمیم در فارکس»؟
تا اینجا بدون کدنویسی جلو آمدیم. حالا نوبت اولین مدل تفسیرپذیر و محبوب مبتدیان است: درخت تصمیم. مزیتش؟ مثل مجموعهای از قوانین اگر/آنگاه فکر میکند و همین آن را برای تریدرهایی که از اندیکاتورها به دنیای ML میآیند، آشنا و قابل توضیح میکند. در این اپیزود روی EURUSD (D1) با چند ویژگی ساده (SMA/RSI/ATR/بازده روزانه) یک درخت میسازیم، بیشبرازشش را کنترل میکنیم، Feature Importance را میخوانیم و خروجی احتمال را به سیگنال قابل معامله تبدیل میکنیم. در پایان یک چکلیست و فایل تمرین CSV هم دارید تا روند را سریع تکرار کنید. برای خواندن سایر مقالات مربوط به این حوزه اینجا کلیک کنید.
مدل یادگیری ماشین درخت تصمیم در فارکس چیست؟ (تصورِ یک «فلوچارت بله/خیر»)
درخت تصمیم مثل یک بازی ۲۰سؤالی است؛ یک فلوچارت از پرسشهای خیلی ساده:
- «آیا RSI پایین است؟»
- «آیا ATR (نوسان) زیاد است؟»
- «آیا قیمت بالاتر از SMA20 است؟»
با هر پاسخ «بله/خیر»، به شاخهٔ بعدی میرویم تا در نهایت به یک تصمیم برسیم: «بالا میرود/پایین میآید».
پس خروجی مدل، یک قانون چندمرحلهای است که از دادههای گذشته یاد گرفته شده.
چرا یادگیری ماشین درخت تصمیم برای شروع عالی است؟
- فهمپذیر: نتیجه به شکل چند قانون اگر/آنگاه است؛ میتوانید آن را برای خودتان و مخاطب توضیح دهید.
- بدون دردسر مقیاسدهی: برخلاف بعضی مدلها، لازم نیست ویژگیها را نرمالسازی کنید.
- سریع و سبک: برای دادههای عادی، سریع آموزش میبیند.
مدل یادگیری ماشین درخت تصمیم چطور «بهترین سؤال» را انتخاب میکند؟
در هر گره، مدل بین همهٔ «سؤالهای ممکن» (مثلاً «RSI ≤ ۳۰؟») میگردد تا ببیند کدام سؤال گروهها را تمیزتر جدا میکند.
«تمیزتر» یعنی بعد از تقسیم، هر گروه بیشتر از یک کلاس تشکیل شده باشد (مثلاً بیشترشان «بالا» باشند).
این تمیزی را با معیارهایی مثل Gini یا Entropy میسنجند. لازم نیست فرمولها را حفظ کنید؛ کافی است بدانید:
- Gini/Entropy فقط یک راه برای سنجش «مرتب شدن برچسبها» بعد از تقسیم هستند.
- هرچه عدد بهتر شود، یعنی سؤال بهتری پیدا کردهایم.
بیشبرازش یعنی چه و چطور کنترلش کنیم؟
اگر درخت را «ول» کنیم، آنقدر شاخه میسازد تا تقریباً همهٔ جزئیات و نویز دادهٔ گذشته را حفظ کند؛ روی گذشته عالی، روی آینده ضعیف!
برای جلوگیری از این اتفاق:
- عمق درخت را محدود میکنیم: max_depth=3/5/7
- حداقل تعداد نمونه در برگ را زیاد میگذاریم: min_samples_leaf=20/50
- بعداً هرس (Pruning) هم میتوانیم انجام بدهیم.
ساده بگوییم: درخت کوتاهتر + برگهای بزرگتر = قوانین کلیتر و قابلاعتمادتر.
چه ویژگیهایی به درد درخت تصمیم میخورند؟
- شاخصهای ساده مثل SMA20, RSI14, ATR14, return_1d برای شروع عالیاند.
- درخت با مرزهای «آستانهای» راحت است (کم/زیاد، بالا/پایین).
- نیازی نیست ویژگیها را استاندارد کنید؛ درخت با مقیاسها کنار میآید.
کِی از یادگیری ماشین درخت تصمیم در فارکس استفاده نکنیم؟
- وقتی رابطهها خیلی پیوسته و نرم باشند (مثلاً یک شیب خطی واضح)، درختهای ساده ممکن است پلهای و ناپیوسته تصمیم بگیرند.
- وقتی دقت خیلی مهم است و داده پیچیده، بهتر است سراغ مدلهای ترکیبیتر (مثل Random Forest یا Gradient Boosting) برویم—البته بعد از اینکه مفهوم درخت را فهمیدیم.
چند اصطلاح را خیلی ساده به ذهن بسپارید
- Node (گره): همان سؤال «اگر/آنگاه».
- Leaf (برگ): پایان شاخه؛ تصمیم نهایی.
- Depth (عمق): چند بار سؤال پرسیدهایم تا به تصمیم برسیم.
- Feature Importance: نشان میدهد کدام ویژگیها نقش بیشتری در این فلوچارت داشتهاند.
شروع امن برای تنظیمات (هایپرپارامترها)
برای اولین تلاش، این تنظیمات اغلب متعادل و امن هستند:
- criterion=”gini” (یا “entropy”)
- max_depth=5 (اگر خیلی پیچیده شد، ۳؛ اگر ساده شد، ۷)
- min_samples_leaf=20 (اگر هنوز بیشبرازش است، ۵۰ را امتحان کنید)
- random_state=42 (برای تکرارپذیری)
نتیجهٔ مورد انتظار در فاز یادگیری ماشین درخت تصمیم در فارکس
با این چند ویژگی ساده، در فارکس معمولاً به Accuracy حدود ۵۲–۶۰٪ میرسیم. این طبیعی است؛ مهم این است که:
- قوانین را بفهمیم و پایدار باشند.
- خروجی احتمال را به سیگنال قابل معامله تبدیل کنیم (با آستانههای ۰٫۵۵/۰٫۴۵ و منطقهٔ خنثی).
- در اپیزودهای بعدی، ارزیابی را واقعگرایانهتر کنیم (Walk-Forward، هزینههای معاملاتی، مدیریت ریسک).
مسیر عملی شما (چکلیست فکری یادگیری ماشین درخت تصمیم در فارکس قبل از کد)
- هدف ساده: پیشبینی «بالا/پایین فردا».
- داده تمیز: ستونهای پایه + ویژگیهای ساده (SMA/RSI/ATR/بازده).
- تقسیم زمانی: Train/Valid/Test پشت سر هم (نه تصادفی).
- درخت با محدودیت: max_depth و min_samples_leaf را معقول بگذارید.
- ارزیابی متعادل: فقط Accuracy نه—Precision/Recall/F1 و Confusion Matrix هم ببینید.
- قانون معاملاتی: آستانهٔ دوطرفه برای تبدیل احتمال به سیگنال + منطقهٔ خنثی.
- تفسیر قوانین: ۲–۳ قانون اول را به زبان ساده برای خودتان شرح دهید.
مدل یادگیری ماشین درخت تصمیم در فارکس با کدنویسی Python
قبل از هر چیز: ابزارهایی که باید نصب کنید
گزینه A) مسیر ساده با Anaconda
- دانلود Anaconda (نسخه Python 3.x).
- بعد از نصب، از منوی Start ویندوز باز کنید: Anaconda Navigator یا Anaconda Prompt.
- اگر Navigator را باز کردید، میتوانید Jupyter Notebook را از آن اجرا کنید (یک دکمه دارد).
- اگر با ترمینال راحتترید، Anaconda Prompt را باز کنید.
ساخت محیط کار (environment) پیشنهادی:
در Anaconda Prompt (یا PowerShell اگر Anaconda را به PATH اضافه کردهاید) بزنید:
|
۱ |
conda create -n forex-ml python=۳.۱۰ -yconda activate forex-mlconda install -y pandas scikit-learn matplotlib |
گزینه B) مسیر VS Code
- دانلود و نصب VS Code.
- داخل VS Code از قسمت Extensions افزونه Python را نصب کنید.
- یک ترمینال در VS Code باز کنید: View →
اگر Anaconda ندارید و میخواهید با pip بروید:
در PowerShell یا ترمینال VS Codepython -m venv .venv. .\.venv\Scripts\Activate.ps1 اگر خطا داشت:
|
۱ |
Set-ExecutionPolicy -Scope CurrentUser RemoteSignedpip install --upgrade pippip install pandas scikit-learn matplotlib |
نکته: اگر PowerShell اجازه اجرای دستور Activate.ps1 نداد، یکبار این را بزنید:
|
۱ |
Set-ExecutionPolicy -Scope CurrentUser RemoteSigned |
۱- فایل داده و پوشه پروژه
- یک پوشه بسازید، مثلاً: C:\ForexML\Episode06\
- فایل دادهٔ خودتان از EURUSD را به نام csv داخل همین پوشه بگذارید.
- ستونهای لازم: date, open, high, low, close, volume
- ترتیب تاریخ از قدیم به جدید باشد.
اگر همین حالا داده ندارید، میتوانید یک CSV نمونه بسازید و بعداً با دادهٔ واقعی جایگزین کنید. (در اپیزودهای شما قبلاً داده واقعی دارید.)
۲- فایل نوتبوک یا اسکریپت بسازید
مسیر Jupyter Notebook (خیلی راحت برای شروع)
در Anaconda Prompt:
|
۱ |
conda activate forex-mlcd C:\ForexML\Episode06jupyter notebook |
یک نوتبوک جدید بسازید (New → Python 3) و سلولهای زیر را بهترتیب اجرا کنید.
مسیر VS Code (اگر با ادیتور راحتترید)
- یک فایل جدید بسازید: py یا یک Jupyter Notebook (.ipynb) ایجاد کنید.
- مطمئن شوید Interpreter همان محیطی است که ساختید (بالای VS Code قابل انتخاب است).
۳- کد گامبهگام ساده و کوتاه
کتابخانهها و خواندن داده
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ |
import pandas as pd import numpy as np # مسیر فایل را مطابق سیستم خودتان تنظیم کنید df = pd.read_csv("EURUSD_D1.csv", parse_dates=["date"]) df = df.sort_values("date").reset_index(drop=True) df.head() |
ساخت ویژگیهای ساده (Features)
ما ۴ ویژگی اولیه میسازیم : SMA20، RSI14، ATR14، و بازده روزانه (return1).
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ ۱۰ ۱۱ ۱۲ ۱۳ ۱۴ ۱۵ ۱۶ ۱۷ ۱۸ ۱۹ ۲۰ ۲۱ ۲۲ ۲۳ |
def sma(s, n): return s.rolling(n).mean() def rsi(s, n=۱۴): d = s.diff() up = d.clip(lower=۰) dn = (-d).clip(lower=۰) rs = up.rolling(n).mean() / (dn.rolling(n).mean() + 1e-۹) return ۱۰۰ - ۱۰۰/(۱+rs) def atr(df, n=۱۴): hi, lo, cl = df["high"], df["low"], df["close"] tr = pd.concat([ (hi - lo), (hi - cl.shift(۱)).abs(), (lo - cl.shift(۱)).abs() ], axis=۱).max(axis=۱) return tr.rolling(n).mean() df["sma20"] = sma(df["close"], ۲۰) df["rsi14"] = rsi(df["close"], ۱۴) df["atr14"] = atr(df, ۱۴) df["return1"] = df["close"].pct_change() |
برچسب هدف (جهت فردا)
|
۱ ۲ |
df["target_up"] = (df["close"].shift(-۱) > df["close"]).astype(int) df = df.dropna().reset_index(drop=True) |
۴- تقسیم زمانی: Train / Valid / Test
نکتهٔ خیلی مهم: در دادهٔ زمانی تصادفی تقسیم نکنید. از اول تا آخر زمان را حفظ کنید.
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ ۱۰ ۱۱ ۱۲ ۱۳ ۱۴ ۱۵ |
features = ["sma20", "rsi14", "atr14", "return1"] target = "target_up" n = len(df) train_end = int(۰.۷ * n) valid_end = int(۰.۸۵ * n) X_train = df.loc[:train_end-۱, features] y_train = df.loc[:train_end-۱, target] X_valid = df.loc[train_end:valid_end-۱, features] y_valid = df.loc[train_end:valid_end-۱, target] X_test = df.loc[valid_end:, features] y_test = df.loc[valid_end:, target] |
۵- ساخت اولین مدل یادگیری ماشین درخت تصمیم در فارکس ( (Decision Tree
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ ۱۰ ۱۱ ۱۲ ۱۳ ۱۴ ۱۵ ۱۶ ۱۷ |
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier( criterion="gini", # یا "entropy" max_depth=۵, # عمق معقول برای شروع min_samples_leaf=۲۰, # حداقل نمونه در برگها random_state=۴۲ ) tree.fit(X_train, y_train) # خروجی احتمال (احتمال بالا رفتن) proba_valid = tree.predict_proba(X_valid)[:, ۱] proba_test = tree.predict_proba(X_test)[:, ۱] # برچسب صفر/یک با آستانه ۰.۵ pred_valid = (proba_valid >= ۰.۵).astype(int) pred_test = (proba_test >= ۰.۵).astype(int) |
اگر دیدید مدل «خیلی خوب» عمل میکند، احتمالاً بیشبرازش است. با max_depth کمتر یا min_samples_leaf بزرگتر تست کنید.
۶- ارزیابی ساده مخصوص شروع
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ ۱۰ ۱۱ ۱۲ |
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix def show_metrics(y_true, y_pred, name): print(f"\n== {name} ==") print("Accuracy :", round(accuracy_score(y_true, y_pred), ۳)) print("Precision:", round(precision_score(y_true, y_pred, zero_division=۰), ۳)) print("Recall :", round(recall_score(y_true, y_pred, zero_division=۰), ۳)) print("F1 :", round(f1_score(y_true, y_pred, zero_division=۰), ۳)) print("Confusion:\n", confusion_matrix(y_true, y_pred)) show_metrics(y_valid, pred_valid, "VALID") show_metrics(y_test, pred_test, "TEST") |
عددهای ۵۵–۶۰٪ برای Accuracy در این مرحله طبیعی است. مهم این است که بدانیم کجا اشتباه میزنیم (Confusion Matrix) و بعداً به سیگنال قابل معامله برسیم.
۷- تبدیل احتمال به «سیگنال معاملاتی» ساده
بهجای آستانه ۰٫۵، یک منطقه خنثی بگذارید تا تریدهای بیکیفیت کم شود:
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ |
import numpy as np th_buy = ۰.۵۵ # احتمال بالا رفتن ≥ ۰.۵۵ → خرید th_sell = ۰.۴۵ # احتمال بالا رفتن ≤ ۰.۴۵ → فروش signals = np.where(proba_test >= th_buy, ۱, np.where(proba_test <= th_sell, -۱, ۰)) # ۱ = خرید، -۱ = فروش، ۰ = بدون سیگنال pd.Series(signals).value_counts() |
ایده: آستانهها را بالاتر ببرید (مثلاً ۰.۶۰/۰.۴۰) تا تعداد سیگنالها کمتر اما «کیفیتر» شود.
۸- یک نگاه کوچک به داخل مدل یادگیری ماشین درخت تصمیم (تفسیر ساده)
اهمیت ویژگیها
|
۱ ۲ |
fi = pd.Series(tree.feature_importances_, index=features).sort_values(ascending=False) print(fi) |
این خروجی میگوید کدام ویژگیها بیشتر در تصمیمگیری نقش داشتهاند.
قوانین متنی
|
۱ ۲ |
from sklearn.tree import export_text print(export_text(tree, feature_names=features)) |
۹- نصبها و اجرا—خلاصه دستورات
اگر Anaconda دارید (پیشنهادی)
|
۱ ۲ ۳ ۴ ۵ ۶ |
# Anaconda Prompt conda create -n forex-ml python=۳.۱۰ -y conda activate forex-ml conda install -y pandas scikit-learn matplotlib cd C:\ForexML\Episode06 jupyter notebook |
اگر با VS Code + venv میروید
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ |
# PowerShell یا Terminal VS Code python -m venv .venv . .\.venv\Scripts\Activate.ps1 pip install --upgrade pip pip install pandas scikit-learn matplotlib # اجرای اسکریپت python episode06_tree.py |
خطای فعالسازی در PowerShell؟
Set-ExecutionPolicy -Scope CurrentUser RemoteSigned را یکبار اجرا کنید و دوباره تلاش کنید.
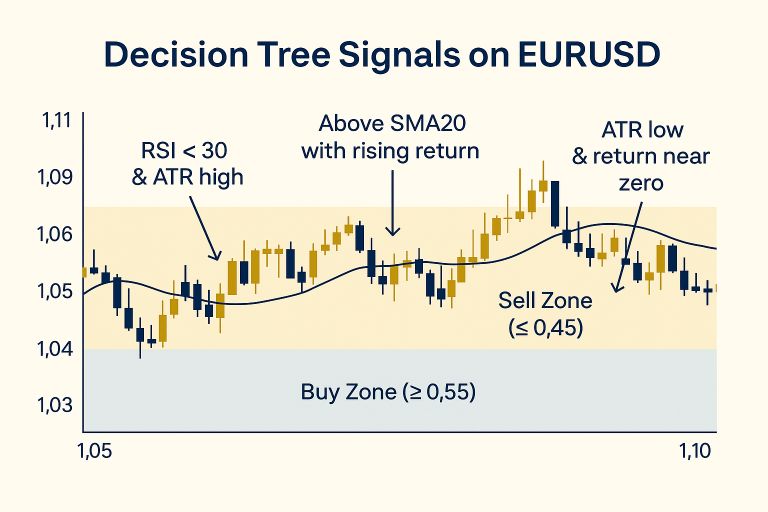
۱۰- تمرینهای کوچک برای شما
۱- max_depth را بین ۳، ۵ و ۷ تست کنید. کدام پایداری بهتری دارد؟
۲- آستانهها را از ۰.۵۵/۰.۴۵ به ۰.۶۰/۰.۴۰ تغییر دهید و تعداد سیگنالها را مقایسه کنید.
۳- ۲ قانون اول درخت را استخراج کنید و کنار چند نقطه از نمودار EURUSD (D1) یادداشت کنید.
چکلیست و فایل تمرینی (آماده دانلود)
- درختها به مقیاس داده حساس نیستند (نیازی به StandardScaler نیست)؛ اما بیشبرازش را همیشه کنترل کنید.
- تقسیم داده باید زمانی باشد (آینده را به گذشته ندهید).
- در اپیزود ۷ «Walk-Forward» را یاد میگیریم تا ارزیابیمان واقعیتر شود.
منابع مورد استفاده در یادگیری ماشین درخت تصمیم در فارکس
-
ISL — بخش Classification Trees
-
Babypips — مقدمات اندیکاتورها (SMA/RSI/ATR)
-
Investopedia — RSI/ATR/SMA
-
Depth Market Pro — مقالات داخلی سری
