
مدل یادگیری ماشین در فارکس (محتوای آموزشی و پایه)
مقدمه ML در فارکس
فارکس یکی از بزرگترین و پویاترین بازارهای مالی جهان است؛ بازاری که هر روز میلیاردها دلار در آن معامله میشود. اما در چنین بازاری، تصمیمگیری تنها بر اساس احساس یا چند اندیکاتور کلاسیک کافی نیست. معاملهگر مدرن نیاز دارد ابزاری داشته باشد که بتواند دادههای عظیم بازار را تحلیل کرده، الگوهای پنهان را کشف کند و در نهایت تصمیمهای منطقیتری بگیرد. اینجا جایی است که یادگیری ماشین (Machine Learning یا ML) وارد بازی میشود.
یادگیری ماشین در فارکس به زبان ساده یعنی آموزش دادن یک مدل ریاضی یا الگوریتم تا خودش بتواند از روی دادهها «یاد بگیرد» و بدون اینکه ما هر قانون را دستی برایش تعریف کنیم، در آینده تصمیمگیری کند. شاید این مفهوم در ابتدا کمی پیچیده به نظر برسد، اما وقتی قدمبهقدم جلو برویم، میبینیم که حتی با ابزار سادهای مثل اکسل هم میتوان پایههای ML را تجربه کرد.
این مقالهی کامرستون (پایهای) طراحی شده تا مسیر کامل ۱۶ اپیزود آموزشی مدل یادگیری ماشین در فارکس را در اختیار شما بگذارد. اگر تازه وارد هستید و نمیدانید از کجا شروع کنید، همینجا نقطهی ورود شماست. اگر هم اپیزودهای جداگانه را خواندهاید، این مقاله نقش نقشه راه و مرجع اصلی را برایتان دارد.
TL;DR (خلاصه کل مقالات مدل یادگیری ماشین در فارکس)
اگر وقت ندارید کل مقاله را بخوانید، این چند خط کافی است:
- ما یک سفر آموزشی ۱۶ اپیزودی طراحی کردهایم که از صفر مطلق شروع میشود.
- ابتدا یاد میگیریم چرا ML در فارکس اهمیت دارد و چه تفاوتی با تحلیل سنتی دارد.
- سپس دادههای خام را تمیز میکنیم و ویژگیهای اولیه (Return، SMA، RSI، ATR) میسازیم.
- بعد یاد میگیریم چطور موفقیت یک سیستم معاملاتی را بسنجیم (Accuracy، Profit Factor، MDD، Sharpe).
- در ادامه وارد اولین مدلهای واقعی ML میشویم (رگرسیون خطی و لجستیک) و قدمبهقدم به سمت مدلهای پیشرفتهتر میرویم.
- هدف این مسیر آموزشی این است که در پایان، شما بتوانید یک مدل ML را روی EURUSD یا هر جفتارز دیگری پیادهسازی کرده و نتایج آن را تحلیل کنید.
تاریخچه و پیشزمینه استفاده از الگوریتمها در بازارهای مالی
بازارهای مالی همیشه بر پایهی داده و تصمیمگیری ساخته شدهاند. اگر به گذشته نگاه کنیم، میبینیم که حتی در قرن نوزدهم، معاملهگران با دفتر و قلم، قیمتها را یادداشت میکردند و بر اساس الگوهای ساده تصمیم میگرفتند. اما از همان زمان یک دغدغه بزرگ وجود داشت: «چطور میتوانیم از میان این همه داده، الگوهایی پیدا کنیم که تکرارپذیر باشند؟» همین پرسش باعث شد ابزارهای آماری و سپس الگوریتمها وارد بازارهای مالی شوند.
آغاز با اندیکاتورهای کلاسیک
اولین نسل ابزارها بسیار ساده بودند. اندیکاتورهایی مثل میانگین متحرک (Moving Average) یا MACD به معاملهگران کمک میکردند روندها را شناسایی کنند. این ابزارها بر اساس فرمولهای ریاضی پایه طراحی شده بودند و هنوز هم بهعنوان سنگبنای تحلیل تکنیکال استفاده میشوند. اما محدودیت بزرگشان این بود که فقط بخش کوچکی از داده را در نظر میگرفتند و توانایی یادگیری یا تطبیق با شرایط جدید بازار را نداشتند.
ورود الگوریتمهای معاملاتی (Algorithmic Trading)
در دهههای ۱۹۸۰ و ۱۹۹۰، با پیشرفت کامپیوترها، معاملهگران شروع کردند به کدنویسی قوانین معاملاتی. مثلاً: «اگر SMA50 بالاتر از SMA200 شد، بخر.» این مرحله جهشی بزرگ بود، چون حالا ماشین میتوانست بهجای انسان بهطور خودکار قوانین را اجرا کند. این نوع سیستمها به Algorithmic Trading معروف شدند و باعث افزایش سرعت و دقت معاملات شدند.
عصر معاملات با فرکانس بالا (High Frequency Trading – HFT)
با گسترش دسترسی به اینترنت پرسرعت در دهه ۲۰۰۰، نسل جدیدی از الگوریتمها پدیدار شد: معاملات با فرکانس بالا (HFT). در این مدل، الگوریتمها میتوانستند در کسری از ثانیه تصمیمگیری کنند و هزاران معامله انجام دهند. این فناوری به قدری قدرتمند بود که حجم بزرگی از معاملات بازارهای جهانی را در بر گرفت. اما همچنان یک محدودیت اساسی وجود داشت: این الگوریتمها فقط قوانین از پیش تعیینشده را اجرا میکردند و چیزی به نام «یادگیری» در آنها نبود.
ورود مدلهای یادگیری ماشین (Machine Learning)
از سال ۲۰۱۰ به بعد، با رشد دادههای عظیم (Big Data) و افزایش توان پردازش، رویکرد جدیدی شکل گرفت: به جای اینکه قوانین را به ماشین دیکته کنیم، اجازه دهیم خودش از روی دادهها قوانین را یاد بگیرد. این همان یادگیری ماشین (ML) است.
برای مثال، در گذشته یک معاملهگر باید دستی مینوشت: «اگر RSI زیر ۳۰ باشد و SMA20 صعودی باشد، احتمال افزایش قیمت زیاد است.» اما با ML، کافی است دادههای گذشته را به مدل بدهیم. مدل خودش میتواند بفهمد که چنین الگویی وجود دارد و حتی روابط پنهانتری را هم کشف کند.
ML (یادگیری ماشین در فارکس): چرا مهم است؟
فارکس بازاری است که روزانه تریلیونها دلار در آن جابهجا میشود. دادههای این بازار بسیار زیاد و پیچیدهاند. روشهای سنتی برای چنین حجم دادهای کافی نیستند. اینجاست که ML ارزش واقعی خود را نشان میدهد:
- توانایی پردازش دادههای عظیم در زمان کوتاه
- یافتن الگوهایی که چشم انسان قادر به دیدنشان نیست
- سازگاری با شرایط جدید بازار
به همین دلیل، امروزه بسیاری از صندوقهای سرمایهگذاری و حتی معاملهگران فردی به سمت استفاده از ML رفتهاند.
کاربردهای عملی مدل یادگیری ماشین در فارکس
یادگیری ماشین فقط یک مفهوم نظری یا موضوع دانشگاهی نیست؛ بلکه امروزه در قلب بسیاری از استراتژیهای معاملاتی واقعی حضور دارد. دلیلش هم روشن است: ML میتواند حجم عظیمی از دادههای بازار فارکس را در زمانی بسیار کوتاه پردازش کرده و الگوهایی را کشف کند که چشم انسان یا حتی روشهای سنتی قادر به دیدنشان نیستند. در ادامه چهار نمونه از مهمترین کاربردهای عملی ML در فارکس را مرور میکنیم.
۱. تشخیص روند (Trend Detection)
یکی از مهمترین پرسشهای هر معاملهگر این است: «بازار در روند صعودی است یا نزولی؟» روشهای سنتی معمولاً از اندیکاتورهایی مثل SMA یا MACD برای این کار استفاده میکنند. اما ML در فارکس میتواند ترکیب پیچیدهتری از دادهها را در نظر بگیرد.
مثلاً مدل میتواند همزمان وضعیت بازده روزانه (Return)، قدرت بازار (RSI)، و میزان نوسان (ATR) را بررسی کند و تشخیص دهد که آیا حرکت فعلی بخشی از یک روند پایدار است یا فقط یک نوسان کوتاهمدت.
در مثال EURUSD، یک مدل ML توانست در بازهای که معاملهگران سنتی آن را رِنج (خنثی) میدیدند، الگوهای کوچکی کشف کند که نشان میداد بازار در آستانهی آغاز یک روند صعودی جدید است.
۲. پیشبینی نوسان (Volatility Forecasting)
نوسان یکی از بزرگترین چالشهای فارکس است. معاملهگر باید بداند آیا فردا بازار آرام خواهد بود یا پر از جهشهای ناگهانی. اندیکاتورهایی مثل ATR فقط میزان نوسان گذشته را نشان میدهند، اما ML میتواند پیشبینی کند که در آینده چه رخ خواهد داد.
برای مثال، یک مدل یادگیری ماشین در فارکس با بررسی دادههای گذشته (از جمله ATR، حجم معاملات و اخبار منتشرشده) میتواند احتمال دهد که در روز آینده نوسان افزایش پیدا میکند. این اطلاعات به معاملهگر کمک میکند سایز پوزیشن را تنظیم کند و حد ضرر مناسبتری بگذارد.
۳. مدیریت ریسک خودکار
یکی از جذابترین کاربردهای مدل یادگیری ماشین در فارکس، مدیریت ریسک خودکار است. بسیاری از معاملهگران تازهکار به خاطر مدیریت ضعیف ریسک دچار ضرر میشوند. اما مدلهای ML میتوانند با توجه به شرایط بازار، پیشنهاد دهند که چه اندازه پوزیشن باز شود یا چه سطحی برای حد ضرر و حد سود انتخاب شود.
فرض کنید مدل یاد بگیرد که در شرایطی که ATR بالاست، بهتر است حجم معامله نصف شود. یا اگر RSI و SMA هر دو سیگنال قوی خرید میدهند، میتوان حجم پوزیشن را کمی افزایش داد. این نوع مدیریت ریسک پویا کمک میکند حساب معاملاتی پایدارتر بماند.
۴. تحلیل اخبار و سنتیمنت (Sentiment Analysis)
بازار فارکس فقط به نمودار قیمت محدود نمیشود؛ اخبار اقتصادی و حتی جو عمومی در شبکههای اجتماعی میتوانند تأثیر بزرگی داشته باشند. اینجاست که یادگیری ماشین با استفاده از پردازش زبان طبیعی (NLP) وارد میشود.
مدلهای NLP میتوانند هزاران تیتر خبری یا پست توییتر را در چند ثانیه تحلیل کنند و بفهمند جو کلی مثبت است یا منفی. مثلاً اگر پیش از اعلام نرخ بهره در آمریکا، سنتیمنت بازار منفی باشد، مدل میتواند هشدار دهد که فشار فروش روی دلار بیشتر خواهد شد.
در عمل، ترکیب دادههای قیمتی با سنتیمنت تحلیلشده توسط ML به معاملهگران یک تصویر جامعتر از بازار میدهد.
چرا این کاربردها مهم هستند؟
این چهار حوزه (تشخیص روند، پیشبینی نوسان، مدیریت ریسک و تحلیل اخبار) تقریباً ستونهای اصلی یک استراتژی معاملاتی موفق هستند. در واقع، اگر یک معاملهگر بتواند از ML در هر یک از این بخشها کمک بگیرد، احتمالاً تصمیمهایش منطقیتر و سودآورتر خواهد بود.
به همین دلیل است که امروزه هم صندوقهای بزرگ سرمایهگذاری و هم معاملهگران خرد، بهطور فزایندهای به سمت استفاده از مدلهای ML در فارکس حرکت میکنند.
مقایسه مدل یادگیری ماشین با روشهای سنتی در فارکس
سالهاست که معاملهگران فارکس از روشهای سنتی برای تحلیل بازار استفاده میکنند. اندیکاتورهایی مانند SMA، MACD، RSI و ابزارهایی مثل خطوط روند یا الگوهای شمعی، پایهی اصلی تحلیل تکنیکال بودهاند. این ابزارها ساده، قابلفهم و محبوباند. اما وقتی بازار پیچیدهتر میشود و حجم دادهها افزایش مییابد، محدودیتهای این روشها آشکار میشود. اینجاست که یادگیری ماشین بهعنوان نسل جدید ابزارها وارد صحنه میشود.
نگاه سنتی: قوانین ثابت و صریح
در روشهای سنتی، معاملهگر معمولاً قوانینی مشخص و تغییرناپذیر تعریف میکند. مثلاً:
- اگر SMA20 بالاتر از SMA50 باشد، خرید انجام بده.
- اگر RSI به زیر ۳۰ برسد، منتظر بازگشت باش.
این قوانین سادهاند، اما دقیقاً همین سادگی نقطه ضعف آنهاست. چرا؟ چون بازار فارکس یک سیستم پویا و پیچیده است که هر روز تغییر میکند. قوانینی که امروز جواب میدهند، ممکن است فردا بیاثر شوند.
نگاه مدرن (ML): یادگیری از دادهها
یادگیری ماشین بر خلاف روشهای سنتی قوانین ثابت ندارد. مدلها از دادههای گذشته یاد میگیرند و بر اساس الگوهای کشفشده، تصمیم میگیرند.
مثلاً به جای اینکه معاملهگر بگوید «فقط وقتی SMA20 بالاتر از SMA50 بود خرید کن»، یک مدل ML میتواند ترکیب SMA، RSI، ATR و Return را بررسی کند و بفهمد چه زمانی این ترکیبها منجر به حرکت صعودی واقعی شدهاند.
به بیان ساده، ML میتواند رابطههای پنهان را ببیند؛ رابطههایی که با چشم انسان یا حتی اندیکاتورهای ساده قابل مشاهده نیستند.
مقایسه عملی: EURUSD
فرض کنیم دادههای EURUSD را بررسی کنیم.
- روش سنتی: معاملهگر میبیند SMA20 بالای SMA50 است و تصمیم به خرید میگیرد.
- روش ML: مدل Logistic Regression همان دادهها را میگیرد و علاوه بر SMA، قدرت RSI و نوسان ATR را هم در نظر میگیرد. مدل در نهایت احتمال ۷۵٪ برای صعود پیشبینی میکند.
هر دو روش به خرید منجر میشوند، اما تفاوت بزرگ این است که در رویکرد ML یک ارزیابی احتمالاتی داریم. معاملهگر میتواند تصمیم بگیرد فقط وقتی وارد معامله شود که احتمال موفقیت بالاتر از یک آستانه (مثلاً ۶۰٪) باشد.
|
ویژگی |
روش سنتی | یادگیری ماشین |
|
قوانین |
ثابت و از پیش تعریفشده | پویا، یادگیرنده از دادهها |
|
انعطافپذیری |
پایین |
بالا |
|
تفسیرپذیری |
ساده و قابلفهم |
گاهی پیچیدهتر |
| دقت روی داده زیاد |
محدود |
توان پردازش بالا |
| خروجی | سیگنال مستقیم (بخر/بفروش) |
خروجی احتمالاتی (مثلاً ۷۰٪ صعود) |
نتیجهگیری این مقایسه
یادگیری ماشین جایگزین کامل روشهای سنتی نیست، بلکه آنها را تکمیل میکند. یک معاملهگر میتواند همچنان از SMA یا RSI بهعنوان ابزار بصری استفاده کند، اما در کنار آن یک مدل ML داشته باشد که با دادههای بزرگ کار میکند و به او تصویر احتمالاتی و دقیقتری میدهد.
به همین دلیل، ترکیب تحلیل سنتی با ML در عمل بهترین نتیجه را میدهد: ساده و قابلدرک، اما در عین حال هوشمند و تطبیقپذیر.
چالشها و محدودیتهای یادگیری ماشین در فارکس
مدل یادگیری ماشین در فارکس در نگاه اول شبیه یک عصای جادویی است: دادهها را به مدل بده و بگذار الگوریتمها خودشان راهحل را پیدا کنند. اما واقعیت این است که ML در فارکس با چالشهای جدی روبهروست. اگر این محدودیتها را ندانیم، ممکن است انتظارات غیرواقعی داشته باشیم یا سرمایهمان را به خطر بیندازیم.
۱. بیشبرازش (Overfitting)
یکی از بزرگترین دشمنان یادگیری ماشین، بیشبرازش است. این اتفاق زمانی میافتد که مدل آنقدر خودش را با دادههای گذشته منطبق میکند که حتی نویزها و نوسانات بیاهمیت را هم «یاد میگیرد».
نتیجه چیست؟
- روی دادههای تاریخی عملکرد عالی دارد.
- اما وقتی با دادههای جدید مواجه میشود، دقت به شدت کاهش مییابد.
مثال: مدلی که روی EURUSD سال ۲۰۲۲ آموزش داده شده و دقت ۸۵٪ دارد، ممکن است روی دادههای ۲۰۲۳ تنها ۵۵٪ درست عمل کند.
راهحل: استفاده از دادههای بیشتر، سادهتر نگه داشتن مدل، و تست روی دادههای خارج از نمونه (Out-of-sample).
۲. کیفیت دادهها
در فارکس دادههای خام همیشه کامل یا دقیق نیستند.
- کندلهای یکشنبه ممکن است الگو را خراب کنند.
- تفاوت تایمزونها باعث ناهماهنگی میشود.
- اسپرد بروکرها متغیر است.
اگر داده بهدرستی تمیز نشود، مدل ML هم گمراه میشود. درست همانطور که ضربالمثل معروف میگوید: Garbage in, garbage out.
۳. تغییر رژیم بازار (Regime Shift)
بازار فارکس همیشه در یک حالت ثابت نیست. گاهی ماهها در یک روند آرام حرکت میکند، و گاهی پر از نوسانات شدید میشود. یک مدل که در دوران آرام بازار خوب عمل کرده، ممکن است در دوران پرنوسان بهکلی بیفایده شود.
این تغییر رژیمها (Regime Shifts) باعث میشوند مدلها نیاز به بازآموزی مداوم داشته باشند. معاملهگر باید بداند که هیچ مدلی «همیشگی» نیست.
۴. تفسیرپذیری پایین
یکی دیگر از مشکلات ML بهویژه در مدلهای پیچیده مثل شبکههای عصبی این است که توضیحپذیری کمی دارند.
- در درخت تصمیم میتوان دید چرا مدل به یک نتیجه خاص رسیده.
- اما در LSTM یا XGBoost ممکن است فقط یک خروجی احتمال داشته باشیم، بدون اینکه دقیقاً بدانیم چرا.
این مسئله برای معاملهگران سنتی که به دنبال دلیل روشن برای هر معامله هستند، میتواند آزاردهنده باشد.
۵. نیاز به منابع محاسباتی
اجرای مدلهای پیچیده به دادههای زیاد و توان پردازش بالا نیاز دارد. معاملهگری که فقط یک لپتاپ معمولی دارد، شاید نتواند بهسادگی مدلهای LSTM یا XGBoost سنگین را اجرا کند. این محدودیت فنی میتواند مانع ورود برخی افراد شود.
جمعبندی این بخش
مدل یادگیری ماشین در فارکس ابزاری قدرتمند است، اما معجزه نمیکند. مدلها میتوانند به معاملهگر کمک کنند تصمیمهای بهتری بگیرد، اما همچنان باید همراه با مدیریت ریسک، بازنگری مداوم و درک محدودیتها استفاده شوند.
به بیان ساده: ML یک دستیار فوقالعاده است، اما جایگزین عقل و تجربهی انسانی نمیشود.
مسیر یادگیری پیشنهادی برای تازهکارها
یکی از پرسشهای همیشگی خوانندگان این است: «اگر بخواهم همین امروز شروع کنم، قدمبهقدم چه کارهایی باید انجام دهم؟» پاسخ به این پرسش اهمیت زیادی دارد، چون بسیاری از تازهکارها به خاطر حجم زیاد اطلاعات دچار سردرگمی میشوند. در این بخش یک نقشه راه ساده و عملی ارائه میکنیم که میتواند نقطه شروعی مطمئن باشد.
۱. شروع با اکسل و دادههای تمیز
قبل از ورود به دنیای کدنویسی، بهتر است اصول اولیه را در یک محیط ساده مثل اکسل تجربه کنید.
- دادهی EURUSD را برای یک دوره مشخص (مثلاً ۲ سال گذشته) دانلود کنید.
- داده را تمیز کنید: کندلهای ناقص را حذف کنید، تایمزون را یکسان کنید.
- اولین ویژگیها مثل Return، SMA20 و RSI14 را در اکسل محاسبه کنید.
این مرحله کمک میکند بفهمید دادهی خام چقدر نیاز به پردازش دارد و چطور میشود آن را به اطلاعات مفید تبدیل کرد.
۲. یادگیری مقدماتی پایتون
وقتی اصول اولیه در اکسل جا افتاد، نوبت به پایتون میرسد. پایتون زبان سادهای است که بهطور گسترده در ML و تحلیل داده استفاده میشود.
- نصب Anaconda یا Google Colab برای شروع کافی است.
- یاد بگیرید چطور داده را وارد کنید (با کتابخانه Pandas).
- کارهای ابتدایی مثل محاسبه میانگین یا ترسیم نمودار را تمرین کنید.
این مرحله شما را آماده میکند تا بعدها مدلهای پیچیدهتر را پیادهسازی کنید.
۳. آشنایی با Scikit-learn
کتابخانه Scikit-learn یکی از بهترین نقاط شروع برای ورود به ML است. با چند خط کد میتوانید یک Logistic Regression یا Random Forest اجرا کنید.
- دادهی تمیز و ویژگیسازیشده را وارد کنید.
- مدل Logistic Regression را آموزش دهید.
- Accuracy و Confusion Matrix را بررسی کنید.
این تجربه همان چیزی است که در اپیزود ۶ شروع کردیم: تبدیل کارهای دستی به اجرای ماشینی.
۴. یادگیری مدلهای پیشرفتهتر
وقتی با Logistic Regression و درخت تصمیم راحت شدید، وقت آن است که سراغ مدلهای قویتر بروید:
- Random Forest → مقاوم در برابر
- XGBoost → یکی از بهترین الگوریتمهای
- LSTM → مخصوص سریهای زمانی مثل فارکس.
اینجا دیگر وارد مرحلهای میشوید که مدلها میتوانند واقعاً در پیشبینی بازار کمکتان کنند.
۵. تمرکز بر مدیریت ریسک
هیچ مدلی—حتی بهترینها—بدون مدیریت ریسک ارزش ندارد. یاد بگیرید چطور:
- سایز پوزیشن را بر اساس ATR یا موجودی حساب تنظیم کنید.
- برای هر معامله حد ضرر مشخص کنید.
- سود و ضرر را در یک ژورنال معاملاتی ثبت کنید.
این بخش همان چیزی است که ML را از یک ابزار آزمایشگاهی به یک دستیار واقعی در معاملات تبدیل میکند.
۶. معرفی منابع آموزشی
برای اینکه مسیر یادگیری سریعتر شود، این منابع میتوانند مفید باشند:
- کتاب Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow
- سایت Babypips (بخش الگوریتمی)
- دورههای مقدماتی پایتون در Coursera یا Udemy
- وبلاگهای تخصصی مثل Towards Data Science و QuantStart
جمعبندی این مسیر
مسیر یادگیری ماشین در فارکس یک ماراتن است، نه یک دوی سرعت. از اکسل شروع کنید، سپس پایتون یاد بگیرید، بعد Scikit-learn را امتحان کنید و در نهایت به سراغ مدلهای پیشرفتهتر بروید. همزمان مدیریت ریسک را فراموش نکنید. اگر این مسیر را طی کنید، در پایان نهتنها ML را درک کردهاید، بلکه توانستهاید آن را در معاملات واقعی به کار بگیرید.
معرفی سری مقالات مدل یادگیری ماشین در فارکس
این سری آموزشی بهصورت اپیزودیک (قسمتبهقسمت) طراحی شده است. هر اپیزود یک قدم کوچک اما ضروری در مسیر یادگیری است. از همان ابتدا تلاش کردهایم زبان مقالهها ساده باشد تا حتی کسانی که هیچ پیشزمینهای از برنامهنویسی یا ریاضیات ندارند، بتوانند همراه شوند.
نماد اصلی که در این سری استفاده میکنیم EURUSD است؛ پرمعاملهترین جفتارز دنیا. دلیل انتخاب آن این است که هم دادههای آن بهوفور در دسترس است و هم رفتارهای نسبتاً قابل پیشبینی دارد که برای مثالهای آموزشی عالی است.
در ادامه، مرور کوتاهی بر چهار اپیزود اول این مسیر خواهیم داشت.
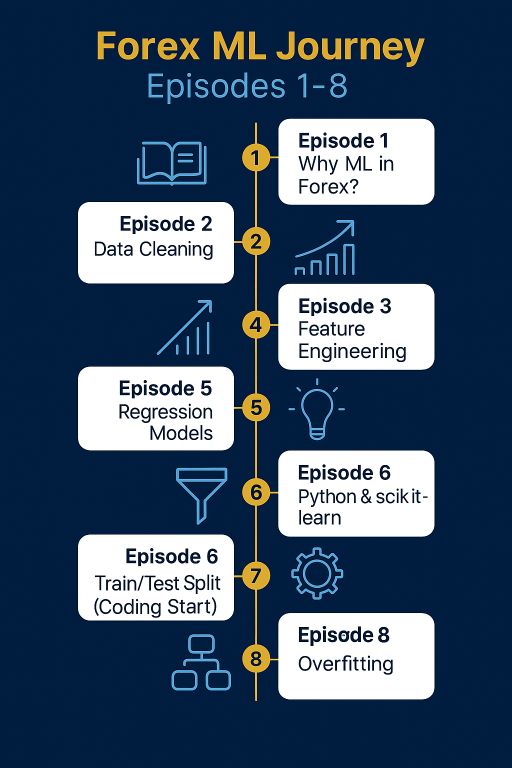
اپیزود ۱ — چرا استفاده از مدل یادگیری ماشین در فارکس؟
در اولین اپیزود، از پایه شروع کردیم: اصلاً چرا باید به سراغ ML برویم؟ پاسخ ساده است: چون روشهای سنتی تحلیل بازار (اندیکاتورهای کلاسیک، تحلیل تکنیکال صرف) دیگر به تنهایی کافی نیستند. بازار امروز پر از داده است و ML به ما کمک میکند از این دادهها ارزش استخراج کنیم.
در این قسمت یک مثال ساده با SMA20 روی EURUSD بررسی شد. دیدیم که حتی یک میانگین متحرک ساده میتواند تا حدی روند بازار را نشان دهد. اما پرسش مهم این بود: «آیا میتوانیم بهتر از این عمل کنیم؟» همین پرسش بود که ما را به دنیای ML هدایت کرد.“بیشتر بخوانید”
اپیزود ۲ — داده چیست و چرا باید تمیز باشد؟
هیچ مدلی بدون دادهی خوب معنا ندارد. دادههای خام فارکس پر از ایراد هستند:
- کندلهای ناقص (مثلاً کندلهای یکشنبه)
- دادههای تکراری
- تفاوت تایمزونها
در این اپیزود یاد گرفتیم که قبل از هر کاری باید داده را پاکسازی (Data Cleaning) کنیم. مثال EURUSD نشان داد که اگر همین دادهی خام را مستقیماً به مدل بدهیم، مدل به اشتباه میافتد. درست مثل پزشکی که بخواهد با پروندههای پزشکی ناقص بیمار را درمان کند.
تمرین این قسمت شامل پاکسازی داده در اکسل بود؛ از حذف ردیفهای ناقص گرفته تا هماهنگسازی ساعتها.“بیشتر بخوانید”
اپیزود ۳ — ویژگیسازی ساده (Feature Engineering)
وقتی داده تمیز شد، نوبت به ساخت ویژگیها رسید. ویژگیها همان سرنخهایی هستند که به مدل کمک میکنند بفهمد چه اتفاقی در بازار میافتد. در این اپیزود چهار ویژگی مهم ساختیم:
- بازده روزانه (Return) → تغییر نسبی قیمت امروز به دیروز
- SMA20 → نماینده روند کوتاهمدت
- RSI14 → سنجش قدرت بازار
- ATR14 → اندازهگیری نوسان
مثال EURUSD نشان داد که این ویژگیها چطور میتوانند شرایط بازار را بهتر توضیح دهند. تمرین عملی هم ساختن این ستونها در اکسل بود، که بهسادگی با چند فرمول انجام شد.“بیشتر بخوانید”
اپیزود ۴ — معیار موفقیت (Metrics)
فرض کن یک مدل داری که ۶۰٪ مواقع درست پیشبینی میکند. آیا این مدل خوب است؟ شاید بله، شاید هم نه! چون باید بدانیم در کنار دقت (Accuracy)، معیارهای دیگری مثل Profit Factor (نسبت سود به ضرر)، Max Drawdown (بیشترین افت سرمایه) و Sharpe Ratio (بازده تعدیلشده با ریسک) را هم بررسی کنیم.
در این اپیزود مثالهای واقعی EURUSD نشان داد که یک سیستم میتواند Accuracy بالایی داشته باشد اما بهخاطر ضررهای بزرگ، در نهایت بازنده باشد. همینطور دیدیم که شاخص Sharpe کمک میکند سود را در کنار نوسان بسنجیم.
این قسمت در واقع پلی بود بین «ساخت ویژگی» و «ساخت مدل»، چون حالا میدانیم چطور موفقیت یا شکست یک سیستم را اندازهگیری کنیم.“بیشتر بخوانید”
اپیزود ۵ — اولین مدل یادگیری ماشین در فارکس(رگرسیون ساده روی EURUSD)
پس از اینکه داده را تمیز کردیم، ویژگیها را ساختیم و معیارهای موفقیت را شناختیم، وقت آن رسید که برای اولین بار یک مدل واقعی ML بسازیم. در این اپیزود سراغ یکی از سادهترین مدلها رفتیم: رگرسیون خطی و لجستیک.
رگرسیون خطی مثل این است که بخواهیم یک خط صاف میان نقاط دادهها رسم کنیم. این خط نشان میدهد وقتی ورودیها (مثلاً RSI، ATR یا SMA20) تغییر میکنند، خروجی (قیمت فردا) چطور واکنش نشان میدهد.
اما بازار فارکس بیشتر شبیه یک سؤال «بله/خیر» است: فردا بالا میرویم یا پایین؟ به همین دلیل رگرسیون لجستیک انتخاب بهتری بود. این مدل خروجی را به شکل احتمال بیان میکند. مثلاً:
- احتمال صعود EURUSD فردا = ۶۸٪
- احتمال نزول = ۳۲٪
این نگاه احتمالاتی به ما کمک کرد تصمیم بگیریم که فقط در شرایطی وارد معامله شویم که احتمال موفقیت بالاتر از یک آستانه (مثلاً ۶۰٪) باشد.
در تمرین این اپیزود، دادههای EURUSD را در اکسل مرتب کردیم و ستون Target را تعریف کردیم (۱ برای صعود، ۰ برای نزول). سپس با ابزار ساده رگرسیون، Accuracy اولیه مدل را محاسبه کردیم. عددی که به دست آمد شاید شگفتانگیز نبود (۵۸–۶۲٪)، اما برای اولین تجربهی ML در فارکس کاملاً هیجانانگیز بود.“بیشتر بخوانید”
اپیزود ۶ — اولین قدم به سمت کدنویسی (Python و Scikit-learn)
تا اینجا همهچیز را بدون کدنویسی یا در اکسل انجام داده بودیم. اما اپیزود ۶ اولین جایی بود که به سراغ پایتون رفتیم. دلیلش هم ساده بود: وقتی دادهها بزرگتر شوند یا بخواهیم مدلهای پیچیدهتر را امتحان کنیم، اکسل دیگر کافی نیست.
در این قسمت با کتابخانه معروف Scikit-learn آشنا شدیم. این ابزار یکی از سادهترین راهها برای پیادهسازی مدلهای یادگیری ماشین است. کدی که نوشتیم چیزی شبیه به این بود:
اینجا X_train و y_train همان ویژگیها و خروجیهای گذشته بودند و X_test و y_test هم بخشی از دادهها که مدل تا حالا ندیده بود.
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ |
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) |
نتیجه جالب بود: همان Accuracy حدود ۶۰٪ که در اکسل دیده بودیم، حالا در پایتون هم ظاهر شد. اما این بار قدرت بیشتری داشتیم: میتوانستیم دادههای بزرگتر را در چند ثانیه پردازش کنیم و حتی معیارهایی مثل Confusion Matrix یا Precision و Recall را هم حساب کنیم.
این اپیزود اولین قدم جدی برای خوانندگانی بود که میخواستند وارد دنیای واقعی الگوریتمنویسی شوند.
اپیزود ۷ — تقسیم دادهها: آموزش و تست
یکی از اشتباهات بزرگ مبتدیها این است که همهی داده را به مدل میدهند و انتظار دارند نتیجه درست باشد. اما در عمل این کار باعث میشود مدل فقط گذشته را حفظ کند و هیچ توانایی برای پیشبینی آینده نداشته باشد.
در اپیزود ۷ یاد گرفتیم باید داده را به دو بخش تقسیم کنیم:
- Training set (آموزش): معمولاً ۷۰٪ داده
- Test set (تست): معمولاً ۳۰٪ داده
گاهی حتی بخش سومی هم وجود دارد به نام Validation set که برای تنظیم پارامترها به کار میرود.
با این کار، مدل روی داده آموزش یاد میگیرد، اما روی داده تست ارزیابی میشود. این شبیه این است که دانشآموزی سر کلاس تمرین کند (Training) و بعد در امتحان نهایی (Test) ببیند آیا واقعاً یاد گرفته یا فقط از بر کرده است.
مثال EURUSD نشان داد که اگر کل دادهها را به مدل بدهیم، Accuracy به شکل غیرواقعی بالا میرود (مثلاً ۸۰٪). اما وقتی بخشی از دادهها را برای تست کنار گذاشتیم، Accuracy واقعی چیزی نزدیک به ۶۰٪ شد. این یعنی مدل واقعاً در پیشبینی آینده محدودیت دارد و باید روی بهبودش کار کنیم.
اپیزود ۸ — جلوگیری از بیشبرازش (Overfitting)
در این مرحله با یکی از بزرگترین چالشهای یادگیری ماشین آشنا شدیم: Overfitting یا همان «بیشبرازش».
Overfitting زمانی رخ میدهد که مدل آنقدر خودش را با دادههای گذشته تطبیق میدهد که کوچکترین جزئیات و نویزها را هم حفظ میکند. نتیجه این است که روی داده آموزش عالی عمل میکند، اما روی داده تست ضعیف است.
برای توضیح ساده، تصور کن دانشآموزی همهی سوالات تمرین معلم را حفظ کرده باشد. در امتحان نهایی اگر سوالها عوض شوند، او هیچ کمکی نمیتواند بکند. این همان Overfitting است.
در فارکس، Overfitting بسیار خطرناک است. چون بازار آینده همیشه با گذشته تفاوت دارد. اگر مدل فقط گذشته را از بر کرده باشد، در عمل معاملهگر را به ضرر میاندازد.
در اپیزود ۸ راهکارهای کاهش Overfitting را بررسی کردیم:
- استفاده از دادهی بیشتر برای آموزش.
- ساده نگه داشتن مدل (مثلاً Logistic Regression بهجای مدلهای خیلی پیچیده در ابتدای کار).
- استفاده از تکنیک Cross-validation (تقسیم داده به چند بخش برای تستهای مختلف).
مثال EURUSD نشان داد مدلی که بیشبرازش دارد ممکن است در Training Accuracy = ۸۵٪ باشد، اما در Test Accuracy = ۵۵٪. همین تفاوت فاحش علامت خطر است.
اپیزود ۹ — درخت تصمیم (Decision Tree)
بعد از Logistic Regression و مدلهای ساده، نوبت به یکی از محبوبترین ابزارهای یادگیری ماشین رسید: درخت تصمیم.
تصور کن میخواهی یک تصمیم بگیری، مثلاً اینکه امروز EURUSD را بخری یا نه. اول از خودت میپرسی: «آیا RSI بالای ۷۰ است؟» اگر بله، احتمالاً بازار اشباع خرید است و باید مراقب باشی. اگر نه، سؤال دوم: «آیا SMA20 صعودی است؟» اگر بله، شاید شرایط مناسبتر باشد. همینطور ادامه میدهی تا به یک نتیجه برسی.
این دقیقاً همان چیزی است که یک Decision Tree انجام میدهد. مدل درختی با استفاده از دادههای تاریخی یاد میگیرد کدام ویژگیها (مثل Return یا ATR) مهمترند و بر اساس آنها شاخههای درخت را میسازد. در نهایت به برگ درخت میرسیم که میگوید «بخر» یا «نفروش».
مزیت درخت تصمیم این است که تفسیرپذیر است؛ یعنی میتوانی مسیر تصمیمگیری مدل را ببینی. مثلاً مدل یاد گرفته که:
- اگر RSI < ۳۰ و SMA20 صعودی → احتمال صعود زیاد است.
- اگر ATR خیلی بالا باشد → پیشبینی سخت است، سیگنال نده.
در اپیزود ۹ روی داده EURUSD یک Decision Tree آموزش دادیم. نتایج نشان داد Accuracy کمی بالاتر از Logistic Regression بود (حدود ۶۳٪)، اما خطر Overfitting هم وجود داشت. برای همین در اپیزودهای بعدی به نسخههای پیشرفتهتر آن پرداختیم.
اپیزود ۱۰ — جنگل تصادفی (Random Forest)
وقتی فهمیدیم یک درخت تصمیم ممکن است زیادی به داده آموزش بچسبد، سراغ جنگل تصادفی رفتیم. همانطور که از اسمش پیداست، این مدل بهجای یک درخت، دهها یا صدها درخت تصمیم میسازد.
ایده ساده است:
- هر درخت روی بخش متفاوتی از داده آموزش میبیند.
- هر درخت یک پیشبینی میدهد.
- در نهایت مدل خروجی همهی درختها را با هم جمع میکند (رأیگیری یا میانگینگیری).
نتیجه این است که خطاهای یک درخت خاص توسط بقیه جبران میشوند. درست مثل اینکه بهجای یک تحلیلگر، نظرات ۱۰۰ تحلیلگر را بگیری.
در اپیزود ۱۰، مدل Random Forest روی داده EURUSD اجرا شد. Accuracy آن به حدود ۶۷٪ رسید. اما نکته مهمتر این بود که مدل ثبات بیشتری پیدا کرد. یعنی برخلاف یک Decision Tree که ممکن بود با تغییر جزئی در داده نتایجش عوض شود، Random Forest مقاومتر بود.
همچنین با ابزارهای داخلی این مدل توانستیم بفهمیم کدام ویژگیها (Return، SMA، RSI، ATR) در تصمیمگیری مهمتر هستند. این برای یک معاملهگر مثل کشف نقشهی ذهنی بازار است.
اپیزود ۱۱ — XGBoost (یادگیری تقویتی)
اگر Random Forest ترکیبی از درختهای تصادفی است، XGBoost یک قدم فراتر میرود: درختها را پشت سر هم میسازد و هر درخت اشتباهات درخت قبلی را اصلاح میکند. این تکنیک به نام Boosting شناخته میشود.
XGBoost یکی از قدرتمندترین الگوریتمها در مسابقات دادهکاوی است. دلیلش این است که هم دقت بالایی دارد و هم نسبت به دادههای نامنظم مقاوم است.
در اپیزود ۱۱ ما یک مدل XGBoost روی داده EURUSD اجرا کردیم. نتیجه چشمگیر بود: Accuracy به حدود ۷۰٪ رسید. اما مهمتر از آن، مدل توانست الگوهایی ظریفتر از Logistic Regression یا Random Forest پیدا کند.
با این حال هشدار دادیم که XGBoost هم میتواند Overfit کند، مخصوصاً اگر پارامترها درست تنظیم نشوند. بنابراین یاد گرفتیم که همیشه باید مدل را با داده تست و معیارهایی مثل Sharpe یا Drawdown بسنجیم، نه فقط Accuracy.
اپیزود ۱۲ — انتخاب ویژگی و اهمیت آن (Feature Selection)
تا اینجا با چندین مدل کار کردیم، اما همیشه با همان ۴ ویژگی ساده (Return، SMA20، RSI14، ATR14). در اپیزود ۱۲ پرسش مهمی مطرح شد: «آیا همهی ویژگیها ارزشمند هستند؟»
گاهی داشتن ویژگیهای زیاد نه تنها کمکی نمیکند، بلکه باعث میشود مدل گیج شود یا Overfit کند. بنابراین نیاز داریم بهترین ویژگیها را انتخاب کنیم.
در این اپیزود با چند روش انتخاب ویژگی آشنا شدیم:
- Feature Importance: همان چیزی که Random Forest یا XGBoost به ما میدهند.
- Correlation Analysis: بررسی همبستگی ویژگیها با هدف (Target).
- Stepwise Selection: اضافه یا حذف تدریجی ویژگیها و بررسی تاثیر آنها.
مثال EURUSD نشان داد که بعضی ویژگیها (مثل Return کوتاهمدت) اهمیت بیشتری از ATR دارند. وقتی فقط ۲ یا ۳ ویژگی قویتر را به مدل دادیم، Accuracy بهتر شد و مدل پایدارتر کار کرد.
این اپیزود به خواننده یاد داد که کیفیت داده و ویژگیها گاهی مهمتر از نوع مدل است. به قول معروف: Garbage in, garbage out — اگر ورودی بیکیفیت باشد، خروجی مدل هم فایدهای نخواهد داشت.
اپیزود ۱۳ — شبکههای عصبی ساده (Neural Networks)
تا اینجا مدلهای مبتنی بر درخت و رگرسیون را بررسی کردیم. اما دنیای یادگیری ماشین فقط به اینها ختم نمیشود. در اپیزود ۱۳ اولین قدم را به سمت شبکههای عصبی برداشتیم.
شبکه عصبی ساده (Feedforward Neural Network) مثل مجموعهای از گرهها یا نورونهاست که در لایههای مختلف به هم وصل شدهاند. هر نورون ورودیها را میگیرد، وزنها را اعمال میکند و خروجی را به لایه بعدی میفرستد.
در مثال EURUSD، ورودیها همان ویژگیها بودند (Return، SMA، RSI، ATR) و خروجی مدل احتمال صعود یا نزول روز بعد بود.
مزیت شبکه عصبی این است که میتواند روابط غیرخطی پیچیده را یاد بگیرد. اما در مقابل، تفسیرپذیری کمتری دارد؛ یعنی دیگر مثل درخت تصمیم نمیتوانیم به راحتی بگوییم کدام شرط باعث تصمیم نهایی شده است.
در این اپیزود با یک شبکهی کوچک دو لایه روی داده EURUSD کار کردیم. Accuracy به حدود ۶۸٪ رسید. اما نکته اصلی این بود که مخاطب دید چطور الگوریتمهای پیشرفتهتر وارد میدان میشوند.
اپیزود ۱۴ — LSTM (مدلهای دنبالهای برای سریهای زمانی)
فارکس یک سری زمانی (Time Series) است؛ یعنی ترتیب دادهها مهم است. قیمت امروز وابسته به دیروز و روزهای قبل است. برای همین در اپیزود ۱۴ سراغ LSTM (Long Short-Term Memory) رفتیم؛ یکی از معروفترین انواع شبکههای عصبی بازگشتی.
LSTM میتواند وابستگیهای بلندمدت در دادهها را یاد بگیرد. مثلاً اگر EURUSD در دو هفتهی اخیر روند صعودی داشته، LSTM این الگو را تشخیص میدهد و در پیشبینی فردا از آن استفاده میکند.
این اپیزود به خواننده نشان داد که چرا مدلهای کلاسیک مثل Logistic Regression برای دادههای سری زمانی محدودند و چرا شبکههای خاص مثل LSTM طراحی شدهاند.
با دادههای EURUSD، مدل LSTM توانست کمی بهتر از مدلهای قبلی عمل کند و الگوهای روندی بلندمدت را بهتر درک کند.
اپیزود ۱۵ — ارزیابی عملی روی EURUSD و سایر جفتارزها
تا اینجا بیشتر روی EURUSD تمرکز داشتیم. در اپیزود ۱۵ تصمیم گرفتیم ببینیم آیا مدلها روی جفتارزهای دیگر هم کار میکنند یا نه. چون یک مدل اگر فقط روی EURUSD جواب بدهد، ممکن است در عمل محدودیت داشته باشد.
مدل Logistic Regression و Random Forest روی GBPUSD و USDJPY هم تست شدند. نتایج نشان دادند که برخی الگوها مشترکاند (مثلاً تاثیر SMA یا RSI)، اما برخی رفتارها مختص هر جفتارز هستند.
این اپیزود به خواننده یاد داد که همیشه باید مدلها را روی چندین بازار تست کرد و نباید فقط به یک مثال خاص دل بست.
اپیزود ۱۶ — ساخت استراتژی کامل و آیندهی مسیر
آخرین اپیزود فصل اول جایی بود که همهچیز را به هم وصل کردیم. از داده تمیز شروع کردیم، ویژگیها ساختیم، مدلها را آموزش دادیم و ارزیابی کردیم. حالا باید یک استراتژی معاملاتی کامل بسازیم.
در این اپیزود مراحل زیر مرور شدند:
- دریافت داده تمیز EURUSD
- ساخت ویژگیها (Return، SMA20، RSI14، ATR14)
- انتخاب مدل (مثلاً Logistic Regression یا Random Forest)
- ارزیابی با معیارهای موفقیت (Accuracy، Sharpe، MDD)
- تست روی چند جفتارز مختلف
- تعریف مدیریت ریسک (Risk Management) برای استفاده واقعی
همچنین دربارهی آیندهی مسیر صحبت کردیم:
- حرکت از مدلهای سنتی به سمت یادگیری عمیق (Deep Learning)
- استفاده از پردازش زبان طبیعی (NLP) برای تحلیل اخبار فارکس
- ترکیب ML با الگوریتمهای مدیریت ریسک برای سیستمهای معاملاتی پایدار
این اپیزود مثل جمعبندی یک سفر بود؛ سفری که از یک SMA ساده شروع شد و به دنیای پیشرفتهی هوش مصنوعی ختم شد.
جمعبندی نهایی مقاله مدل یادگیری ماشین در فارکس
سری ۱۶ اپیزودی «مدل یادگیری ماشین در فارکس» یک مسیر کامل و آموزشی است:
- در ابتدای راه فهمیدیم چرا ML در فارکس اهمیت دارد.
- دادهها را تمیز کردیم و ویژگیهای ساده ساختیم.
- معیارهای موفقیت را شناختیم و اولین مدلها را ساختیم.
- قدمبهقدم به سمت مدلهای پیچیدهتر (Random Forest، XGBoost، LSTM) رفتیم.
- در نهایت یاد گرفتیم چگونه از این مدلها یک استراتژی واقعی بسازیم.
این مقاله پایه، نقش ستون اصلی را دارد: تمام اپیزودها به آن لینک داده میشوند و خودش هم راهنمای ورود برای تازهواردان است.
منابع پیشنهادی
- Investopedia — Machine Learning in Trading
- Babypips — School of Pipsology (Algorithmic Trading)
- Towards Data Science — Applied ML for Time Series
- QuantStart — Feature Engineering and Strategy Backtesting
- Depth Market Pro — آموزش یادگیری ماشین در فارکس
سلب مسئولیت
تمامی محتوای این مقاله صرفاً جنبهی آموزشی دارد و هیچکدام توصیهی مالی یا سرمایهگذاری محسوب نمیشوند. بازار فارکس بازاری پرریسک است و استفاده از هر استراتژی یا مدل باید با مسئولیت شخصی و همراه با مدیریت ریسک انجام شود.
